本部落格文章僅供學術研究與教育目的使用。 文中所提及的研究方法與範例腳本均經過混淆處理,不具備直接攻擊或利用的可行性。作者撰寫此文的目的在於:
前言
在進行漏洞研究時,了解目標的運作邏輯相當重要,但如果遇到核心邏輯加密,沒辦法直接逆向時該怎麼辦呢?本文由 TeamT5 漏洞研究團隊 D39 的實習生 Shane 帶來一篇如何解開 QNAP 加密 CGI 的方法。
研究起因
在研究 QNAP NAS 的漏洞時, Pre-Auth 的 CGI 攻擊面一直都是 Pwn2Own 的必爭之地,如
authLogin.cgi 以及 privWizard.cgi ,不過在研究新版的 Firmware 時我們發現將 CGI 直接使用 IDA Pro 分析會發現 Code Section 的部分看起來被加密了,導致 ELF 無法被正常解析,也無法使用動態方式進行追蹤以及還原解密後的程式,這便勾起了我們的好奇。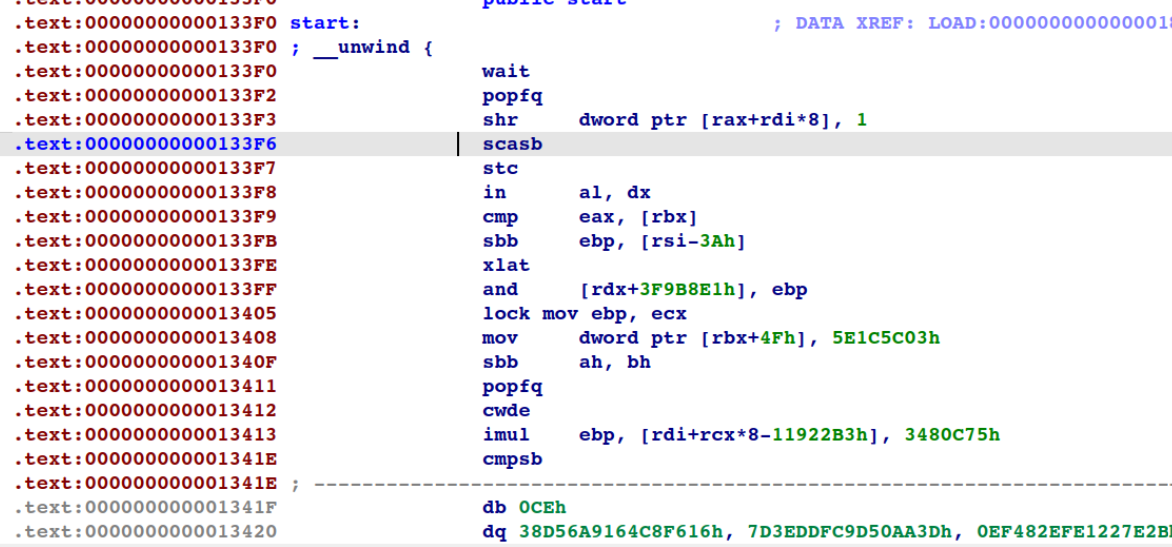
對比新舊版 CGI 以及 Firmware 的差異
在對比後我們發現兩件事情:
1.CGI 的 ELF header 中的
1.CGI 的 ELF header 中的
e_flags (offset = 0x30~0x33) 被寫成 0x40000000,這非常不尋常,因為在 x86_64 系統上通常會被設置為 0 :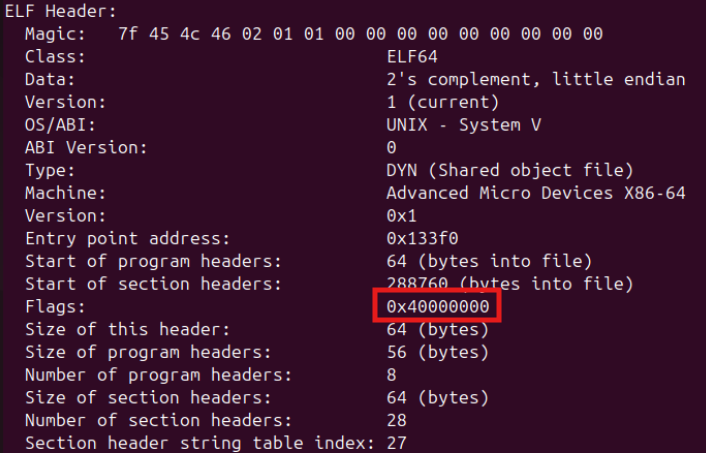
2.將新舊版的 Firmware 直接做差異分析會發現多了一個叫
/lib/modules/5.10.60-qnap/qelf 的 Binary:# find / -name qelf*
/lib/modules/5.10.60-qnap/qelf並且開機的腳本
/etc/init.d/qlsmd.sh 中會將 qelf 以 qelf start 的方式啟動。經過拆解以及比較不同版本的 Firmware 後,發現這個腳本只有在 CGI 也被加密的 Firmware 版本才出現,所以這個
qelf 應該就是跟加密的 cgi 有關係:#!/bin/sh
// ...SKIPPED...
case "$1" in
start)
[ -x /lib/modules/misc/qelf ] && /lib/modules/misc/qelf start
KERNEL_VER=`/bin/uname -r`
if [ "$( /bin/echo ${KERNEL_VER} | /bin/cut -d '.' -f 1 )" -ge 5 ]; then
[ -x /usr/local/sbin/qlsmd ] && /usr/local/sbin/qlsmd &
fi
;;
*)
exit 0
esac在 NAS 上執行
qelf start 可以從 Error Message 發現它疑似會將一個 Kernel Module 解出來,寫到一個暫存檔案後並且用 insmod 載入進 Kernel,所以可以推斷 qelf 算是一個 Loader,並且 Kernel Module 可能跟加解密 ELF 有關。
# /lib/modules/misc/qelf start
insmod /tmp/kmod3403441291: insmod: can't insert '/tmp/kmod3403441291': File exists
qelf: insmod kmod: exit status 17
qelf: setkey: open /dev/memfile0: operation not permittedqelf 在結束後會把暫時解出來的 Kernel Module 刪除,但這邊依然可以使用 strace 抓到 qelf 寫的檔案內容。
# ./strace /lib/modules/misc/qelf start
execve("/lib/modules/misc/qelf", ["/lib/modules/misc/qelf", "start"], 0x7ffecc530488 /* 21 vars */) = 0
// ...
// write tmp ko
futex(0xc00003a548, FUTEX_WAKE_PRIVATE, 1) = 1
fcntl(1, F_GETFL) = 0x8002 (flags O_RDWR|O_LARGEFILE)
fcntl(2, F_GETFL) = 0x8002 (flags O_RDWR|O_LARGEFILE)
openat(AT_FDCWD, "/tmp/kmod3133496389", O_RDWR|O_CREAT|O_EXCL|O_CLOEXEC, 0600) = 3
fcntl(3, F_GETFL) = 0x8002 (flags O_RDWR|O_LARGEFILE)
fcntl(3, F_SETFL, O_RDWR|O_NONBLOCK|O_LARGEFILE) = 0
epoll_create1(EPOLL_CLOEXEC) = 4
pipe2([5, 6], O_NONBLOCK|O_CLOEXEC) = 0
epoll_ctl(4, EPOLL_CTL_ADD, 5, {EPOLLIN, {u32=6077448, u64=6077448}}) = 0
epoll_ctl(4, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=1042808833, u64=9162354833387683841}}) = -1 EPERM (Operation not permitted)
fcntl(3, F_GETFL) = 0x8802 (flags O_RDWR|O_NONBLOCK|O_LARGEFILE)
fcntl(3, F_SETFL, O_RDWR|O_LARGEFILE) = 0
// real qelf.ko
write(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\1\0>\0\1\0\0\0\0\0\0\0\0\0\0\0"..., 32768) = 32768
write(3, "a\1\0\0\0\0\0\0&+\0\0\0\0\0\0\2\0\0\0H\0\0\0\374\377\377\377\377\377\377\377"..., 14552) = 14552
close(3) = 0
// insmod
newfstatat(AT_FDCWD, "/bin/insmod", 0xc00011e448, 0) = -1 ENOENT (No such file or directory)
newfstatat(AT_FDCWD, "/sbin/insmod", {st_mode=S_IFREG|0755, st_size=479688, ...}, 0) = 0
syscall_0x1b7(0xffffffffffffff9c, 0xc0001240b0, 0x1, 0x200, 0, 0) = 0
// ...
+++ exited with 0 +++這樣就可以順利取得
qelf.ko 並且分析。Reverse engineering qelf.ko
qelf.ko 裡面用了非常多跟 mem_file 跟 fops 相關的函數,不過我們比較關注在跟加解密有關的邏輯,有看到疑似在偵測 ptrace 的片段,這邊猜測是在偵測 Debugger:
找到一個函數有
expand 32-byte k 的字串,這讓我們馬上想到了 Chacha20 相關的演算法: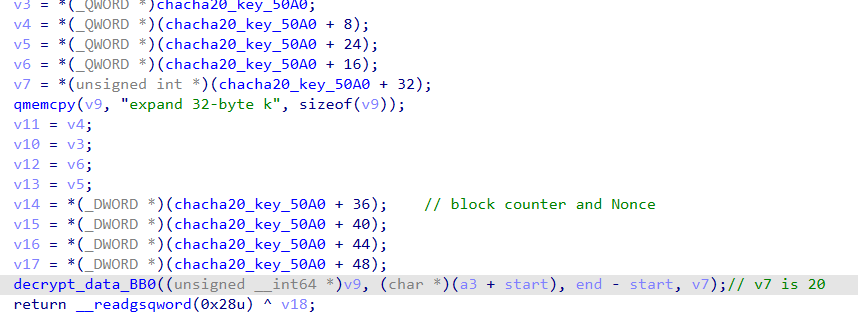
找到看起來像解密的函數,經過逆向發現它是長度為 64 的 Block Cipher,其中每一塊的 Key 會是用類似 Chacha20 改的 Keystream 演算法產生的,並且它會拿 Key 與被加密的 Block 做 XOR :
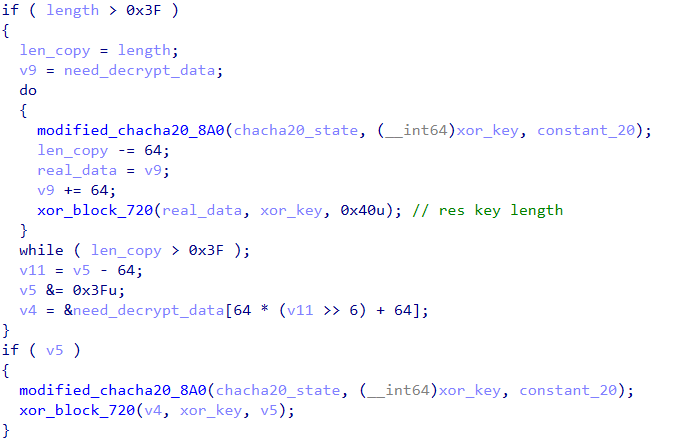
Chacha20 Keystream 函數:

這邊基本上可以確定
qelf.ko 就是負責 Anti-Debugging 以及在 Runtime 解密出真正的 CGI 。Dynamic Debugging
但經過更多的逆向工程我們發現 Chacha20 的 Key 並非 Hard-Code 在
qelf.ko 內,我們懷疑應該是 qelf 這隻在 userland 的 binary 會以某種形式傳給 qelf.ko,但 Go 的逆向其實頗複雜,所以我們打算直接使用動態分析的方式將 Key 給解出來。將官方的韌體解出來後,可以使用 Qemu 將系統模擬起來(參考連結),並且可以結合 System level debug 觀察
qelf.ko 的行為。最終經過動態分析我們發現
1.Decrypter 會先找到 ELF 的
qelf 的解密流程如下:1.Decrypter 會先找到 ELF 的
.text ,這邊是需要被解密的部分。2.假設需要解密的是範圍
0xF0C0 到 0x2E2C5 :
QELF 會以 Page (0x1000) 為一個單位對齊,例如:- 0xF0C0 to 0xFFFF
- 0x10000 to 0x10FFF
- 0x11000 to 0x11FFF
- …
- 0x2D000 to 0x2DFFF
- 0x2E000 to 0x2E2C5
3.解密每一個 Page :
a. 使用變種 Chacha20 作為 Keystream,產生 64 Bytes Key 。
b. 用 XOR 解密該 Block 。
c. 重複以上步驟。
a. 使用變種 Chacha20 作為 Keystream,產生 64 Bytes Key 。
b. 用 XOR 解密該 Block 。
c. 重複以上步驟。
並且我們也在動態分析中成功取得 Chacha20 的 key 以及 nonce。
在寫出解密腳本後,嘗試解密被加密的 CGI,我們發現已經成功解密為正常的 ELF 了:
The missing puzzle for encrypting QELF
在寫出解密腳本後,我們便想到一個有趣的想法:「能不能寫出自己的 QELF 加密器呢?」
由於 QELF 是 XOR 區塊加密(Block Cipher),根據 XOR 的運算特性,在使用同一把金鑰(Key)加密和解密過程在理論上是相同的。
但我們將一般的 ELF 用同樣的流程加密
.text 並且將 e_flags 設為 0x40000000 後,發現並沒有辦法在 NAS 上面跑,應該還有地方沒設好讓 QELF 無法正常解密,經過更多的比對後我們發現 .text Section 的 Flag 也被改變了。Text 段的 Flag 算法:
1.先找到
Start of section headers :$ readelf -h ./bin/authLogin.cgi.old | grep section | grep Start
Start of section headers: 282424 (bytes into file)2.找到
.text Section 的 Number :$ readelf -S ./bin/authLogin.cgi.old | grep text
[12] .text PROGBITS 000000000000ee40 0000ee40
# text section number = 123.
未加密 (v5.2.0) 的 CGI
.text Section Flag 位址在 (section headers)+64*(text section number)+8 的地方。未加密 (v5.2.0) 的 CGI
.text Flag 是:$ xxd -g 8 -s 283200 -l 8 ./bin/authLogin.cgi.old
00045240: 0600000000000000 ........同理,啟用加密 (v5.2.3) 的 CGI
.text Flag 是:$ xxd -g 8 -s 289536 -l 8 authLogin.cgi
00046b00: 0600010000000000 ........因此只要將
.text 修改對應的的 Flag ,我們就能成功把任意 ELF 變成加密的 QELF!
在一般 Linux 機器上編譯一個 Hello world 並且用我們的 Encrypter 腳本加密: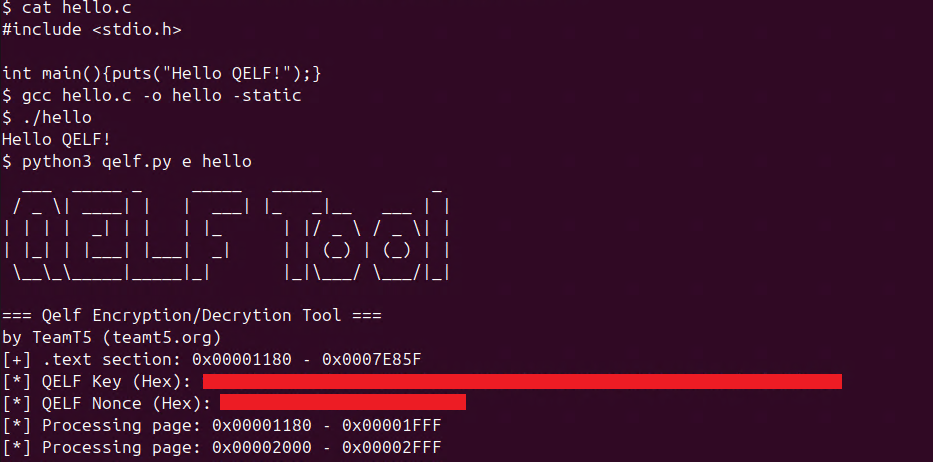
加密完的 ELF 無法在正常的 Linux 上執行:

卻可以在有載入 QELF 的 NAS 上面成功執行:

我們調查了 Firware 版本釋出時間與是否存在 QELF ,發現 QNAP 在 2024 Pwn2Own 之後才實作了 QELF ,將一些重要的 CGI 加密,猜測是想提高逆向成本。
QELF Encrypt/Decrypt Script
經過測試在最新版的
QTS 5.2.8.3332 Build 20251128 仍然可以成功解密 CGI:import struct
import sys
def rotL(x, n):
return ((x << n) | (x >> (32 - n))) & 0xFFFFFFFF
def quarter_round(state, a, b, c, d):
state[a] = (state[a] + state[b]) & 0xFFFFFFFF
state[d] = rotL(state[d] ^ state[a], 16)
state[c] = (state[c] + state[d]) & 0xFFFFFFFF
state[b] = rotL(state[b] ^ state[c], 12)
state[a] = (state[a] + state[b]) & 0xFFFFFFFF
state[d] = rotL(state[d] ^ state[a], 8)
state[c] = (state[c] + state[d]) & 0xFFFFFFFF
state[b] = rotL(state[b] ^ state[c], 7)
def chacha_block(key, counter, nonce, rounds):
constants = [0x61707865, 0x3320646E, 0x79622D32, 0x6B206574]
key_schedule = list(struct.unpack("<IIIIIIII", key))
nonce_schedule = list(struct.unpack("<I", struct.pack("<I", counter))) + list(
struct.unpack("<III", nonce)
)
state = constants + key_schedule + nonce_schedule
initial_state = list(state)
for _ in range(rounds // 2):
quarter_round(state, 0, 4, 8, 12)
quarter_round(state, 1, 5, 9, 13)
quarter_round(state, 2, 6, 10, 14)
quarter_round(state, 3, 7, 11, 15)
quarter_round(state, 0, 5, 10, 15)
quarter_round(state, 1, 6, 11, 12)
quarter_round(state, 2, 7, 8, 13)
quarter_round(state, 3, 4, 9, 14)
final_state = [(s + i) & 0xFFFFFFFF for s, i in zip(state, initial_state)]
return struct.pack("<16I", *final_state)
def chacha_keystream(key, counter, nonce, length, rounds=20):
keystream = bytearray()
current_counter = counter
for i in range(0, length, 64):
keystream_block = chacha_block(key, current_counter, nonce, rounds)
needed = min(64, length - i)
keystream.extend(keystream_block[:needed])
current_counter += 1
return bytes(keystream)
def hex_to_little_endian_bytes(hex_str):
hex_str = hex_str.replace(" ", "").replace("\n", "").strip()
return bytes.fromhex(hex_str)[::-1]
def parse_elf_text_section(filename):
with open(filename, "rb") as f:
elf_header = f.read(64)
if elf_header[:4] != b"\x7fELF":
raise ValueError("Not a valid ELF")
is_64bit = elf_header[4] == 2
if not is_64bit:
raise ValueError("64-bit ELF only")
e_shoff = struct.unpack("<Q", elf_header[40:48])[0]
e_shentsize = struct.unpack("<H", elf_header[58:60])[0]
e_shnum = struct.unpack("<H", elf_header[60:62])[0]
e_shstrndx = struct.unpack("<H", elf_header[62:64])[0]
f.seek(e_shoff + e_shstrndx * e_shentsize)
shstr = f.read(e_shentsize)
shstr_offset = struct.unpack("<Q", shstr[24:32])[0]
shstr_size = struct.unpack("<Q", shstr[32:40])[0]
f.seek(shstr_offset)
shstrtab = f.read(shstr_size)
for i in range(e_shnum):
f.seek(e_shoff + i * e_shentsize)
sh = f.read(e_shentsize)
sh_name_offset = struct.unpack("<I", sh[0:4])[0]
section_name = shstrtab[sh_name_offset:].split(b"\x00", 1)[0].decode()
if section_name == ".text":
sh_offset = struct.unpack("<Q", sh[24:32])[0]
sh_size = struct.unpack("<Q", sh[32:40])[0]
return sh_offset, sh_offset + sh_size - 1
raise ValueError("Cannot find .text section")
def process_file_by_pages(filename, start_offset=None, end_offset=None):
if start_offset is None or end_offset is None:
start_offset, end_offset = parse_elf_text_section(filename)
print(f"[+] .text section: 0x{start_offset:08X} - 0x{end_offset:08X}")
key_part1_le = "xxxxxxxxxxxxxxxx"
key_part2_le = "xxxxxxxxxxxxxxxx"
key_part3_le = "xxxxxxxxxxxxxxxx"
key_part4_le = "xxxxxxxxxxxxxxxx"
nonce_part1_le = "xxxxxxxx"
nonce_part2_le = "xxxxxxxx"
nonce_part3_le = "xxxxxxxx"
key_part1 = hex_to_little_endian_bytes(key_part1_le)
key_part2 = hex_to_little_endian_bytes(key_part2_le)
key_part3 = hex_to_little_endian_bytes(key_part3_le)
key_part4 = hex_to_little_endian_bytes(key_part4_le)
nonce_part1 = hex_to_little_endian_bytes(nonce_part1_le)
nonce_part2 = hex_to_little_endian_bytes(nonce_part2_le)
nonce_part3 = hex_to_little_endian_bytes(nonce_part3_le)
key = key_part1 + key_part2 + key_part3 + key_part4
nonce = nonce_part1 + nonce_part2 + nonce_part3
print(f"[*] QELF Key (Hex): {key.hex()}")
print(f"[*] QELF Nonce (Hex): {nonce.hex()}")
try:
with open(filename, "rb") as src_f:
original_data = bytearray(src_f.read())
page_size = 4096
chunk_size = 64 # 64 bytes per chunk
start_page = start_offset & ~0xFFF # 4KB Align
current_page_start = start_page
page_num = 0
total_decrypted = bytearray()
while current_page_start <= end_offset:
page_end = current_page_start + page_size - 1
actual_start = max(current_page_start, start_offset)
actual_end = min(page_end, end_offset)
if actual_start > actual_end:
break
print(f"[*] Processing page: 0x{actual_start:08X} - 0x{actual_end:08X}")
with open(filename, "rb") as f:
f.seek(actual_start)
process_length = actual_end - actual_start + 1
page_data = f.read(process_length)
if not page_data:
break
counter = 0
page_decrypted = bytearray()
for i in range(0, len(page_data), chunk_size):
chunk = page_data[i : i + chunk_size]
keystream_full = chacha_keystream(key, counter, nonce, 128)
keystream_used = keystream_full[:64]
decrypted_chunk = bytes(
[c ^ k for c, k in zip(chunk, keystream_used[: len(chunk)])]
)
page_decrypted.extend(decrypted_chunk)
# print(f" Chunk {i//chunk_size}, Counter: {counter}, Size: {len(chunk)} bytes")
counter += 1
original_data[actual_start : actual_start + len(page_decrypted)] = (
page_decrypted
)
total_decrypted.extend(page_decrypted)
current_page_start += page_size
page_num += 1
output_filename = filename + "_patched"
with open(output_filename, "wb") as out_f:
out_f.write(original_data)
print("[+] Block cipher xor success!")
except FileNotFoundError:
print(f"[!] Cannot find file '{filename}'")
except Exception as e:
print(f"[!] Error: {e}")
def modify_elf_header_and_text_flag(filename, output_filename=None, mode="d"):
with open(filename, "rb") as f:
data = bytearray(f.read())
if mode == "d":
e_flags_flag = 0
text_flag = 0x0600000000000000
elif mode == "e":
e_flags_flag = 0x40000000
text_flag = 0x0600010000000000
else:
print("[!] You must specify the mode.")
e_flags_offset = 0x30
data[e_flags_offset : e_flags_offset + 4] = struct.pack("<I", e_flags_flag)
print(f"[+] e_flags -> {hex(e_flags_flag)}")
elf_header = data[:64]
e_shoff = struct.unpack("<Q", elf_header[40:48])[0]
e_shentsize = struct.unpack("<H", elf_header[58:60])[0]
e_shnum = struct.unpack("<H", elf_header[60:62])[0]
e_shstrndx = struct.unpack("<H", elf_header[62:64])[0]
shstr_offset = struct.unpack(
"<Q",
data[
e_shoff
+ e_shstrndx * e_shentsize
+ 24 : e_shoff
+ e_shstrndx * e_shentsize
+ 32
],
)[0]
shstr_size = struct.unpack(
"<Q",
data[
e_shoff
+ e_shstrndx * e_shentsize
+ 32 : e_shoff
+ e_shstrndx * e_shentsize
+ 40
],
)[0]
shstrtab = data[shstr_offset : shstr_offset + shstr_size]
for i in range(e_shnum):
sh_offset = e_shoff + i * e_shentsize
sh = data[sh_offset : sh_offset + e_shentsize]
sh_name_offset = struct.unpack("<I", sh[0:4])[0]
section_name = shstrtab[sh_name_offset:].split(b"\x00", 1)[0].decode()
if section_name == ".text":
data[sh_offset + 8 : sh_offset + 16] = struct.pack(">Q", text_flag)
print(f"[+] .text section flags -> {hex(text_flag)}")
break
else:
raise ValueError("Cannot find .text section")
if output_filename is None:
output_filename = filename + ".patched_elf"
with open(output_filename, "wb") as f:
f.write(data)
banner = r""" ___ _____ _ _____ _____ _
/ _ \| ____| | | ___| |_ _|__ ___ | |
| | | | _| | | | |_ | |/ _ \ / _ \| |
| |_| | |___| |___| _| | | (_) | (_) | |
\__\_\_____|_____|_| |_|\___/ \___/|_|
"""
if __name__ == "__main__":
print(banner)
print("=== Qelf Encryption/Decrytion Tool ===")
print("by TeamT5 (teamt5.org)")
if len(sys.argv) != 3:
print(f"Usage: python3 {sys.argv[0]} <e/d> <filename>")
sys.exit(1)
mode = sys.argv[1]
filename = sys.argv[2]
process_file_by_pages(filename)
patched_filename = filename + "_patched"
modify_elf_header_and_text_flag(
patched_filename, output_filename=patched_filename, mode=mode
)
print(f"[+] QELF Process done! File at {patched_filename}")結語
在這篇文章中我們完成了以下研究:
- 發現在 2024 Pwn2Own 結束後, QNAP 將關鍵的 CGI 檔案加密,並且在執行前使用 QELF 機制動態解密出真正的 CGI 。
- 對比加密前以及加密後的 CGI 的 ELF Flag 變化。
- 提取並逆向 qelf.ko,找到 Chacha20 以及 Block Cipher 相關的解密函數。
- 動態分析取得 Chacha20 的 Key, Nonce 以及推測加密 Page 的邏輯。
- 釋出解密 QELF 以及將 ELF 加密成 QELF 的工具。
Related Post
產品與服務
2023.10.16
什麼是漏洞研究?
vulnerability research
產品與服務
2023.10.30
什麼是資安漏洞? 資安漏洞有分級嗎?
vulnerability research